[Ed. Note: After this post, Mr. Kriesel had a follow-up call with Rick Dastin, Corporate Vice President Office and Solutions, and Francis Tse, Imaging System Architect at Xerox Corporation. His post about it is here. My previous post, Confused photocopiers randomly rewriting scanned documents, concerns an article by Peter Bright from arstechnica.com about Mr. Kriesel’s initial findings.]
By David Kriesel (German computer scientist) from dkriesel.com:
Please see the “News / Edits” section as I will post edits in there from now on in order not to make total crap out of the Paper’s outline. In this way, I keep this article up-to-date for future visitors and also write new blog posts on the topic for RSS users.
In this article I present in which way scanners / copiers of the Xerox WorkCentre Line randomly alter written numbers in pages that are scanned. This is not an OCR problem (as we switched off OCR on purpose), it is a lot worse – patches of the pixel data are randomly replaced in a very subtle and dangerous way: The scanned images look correct at first glance, even though numbers may actually be incorrect. Without a fuss, this may cause scenarios like:
- Incorrect invoices
- Construction plans with incorrect numbers (as will be shown later in the article) even though they look right
- Other incorrect construction plans, for example for bridges (danger of life may be the result!)
- Incorrect metering of medicine, even worse, I think.
To make things even more worse: The copiers in question are the common Xerox WorkCentres, and Xerox seemed to be unaware of the issue until we found out about it last Wednesday. Whats more, not only one different WorkCentre model seems to be affected, as we tested at least two with this issue (Xerox WorkCentre 7535 and 7556). Additionally, the current software release, as installed by xerox support, did not solve the issue, thus, the issue existed on the very old release we had installed, as well as on a very new one. The error has been confirmed by a xerox rental firm in the meantime, and Xerox is investigating as well, so it does not seem to be some dumb handling error or something similar (if I was thinking this, I of course would not publish it here).
As a result, anyone using those WorkCentres has to ask himself:
- How many incorrect documents (even though they look correct!) did I produce during the last years by scanning with xerox machines? Did I even give them to others?
- What dangers are imposed by such possible document errors? Is there a danger of life for someone?
- Can I be sued for such errors?
Even though Xerox seems eager to solve the issue, because of the possible dangers an immediate publication of the issue is advisable. This is what I want to do with this article.
The rest of the article is organized as follows.
- By showing some real world examples I outline how we got aware of the issue, and how subtle it is. As it is hard to believe that scan copiers randomly alter written numbers, picture evidence is provided. (At first, I thought someone makes fun of my with this error, too
 ).
). - After that, I give some technical detail and describe the scan parameters set.
- Also, there will be a short manual how to reproduce this error.
Edits / News (newest first)
Edit5, Aug 6. 2002 CEST: Today, I had half an hour of conference call with two of Xerox’s leaders, and we sorted things out. Here is an upshot of the facts.
Edit4, Aug 6, 1532 CEST: There is a possible work around for the issue.
Edit3, Aug 6. 0943 CEST: According to my current blog post, there is now a section of reportedly affected devices added to the tech section of this article.
Edit2, Aug 5th, 1517 CEST: There are first emails coming in by people able to reproduce the error. Also: There might other product lines be affected! Trying to get more information. Click here for the corresponding blog post – the reason for the edits on this original article is to keep this page updated even though publishing new blog posts.
Edit: In the last section, it is now sketched that the reason for the issue may be a misconfigured JBIG 2 compression.
Examples and how we found out
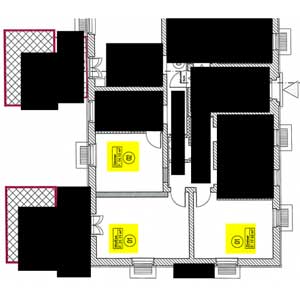
We got aware of the problem by scanning some construction plan last Wednesday and printing it again. Construction problems contain a boxed square meter number per room. Now in some rooms, we found beautifully lay-outed, but utterly wrong square meter numbers. You really have to read the numbers to find out; this is why it is so hard to find out. In the present case, we found out because one room in the construction plan was – as the copy told us – about 22 square meters large, whereas the next room, a lot larger, was assigned a label with 14 square meters.
Firstly, I present to you a complete original version of the affected construction plan part. After this, the wrong numbers will be presented. Click to enlarge. I added the yellow marks myself to show you where the errors will occur. Let us name the upper one “place 1”, the lower left “place 2” and the lower right “place 3”.
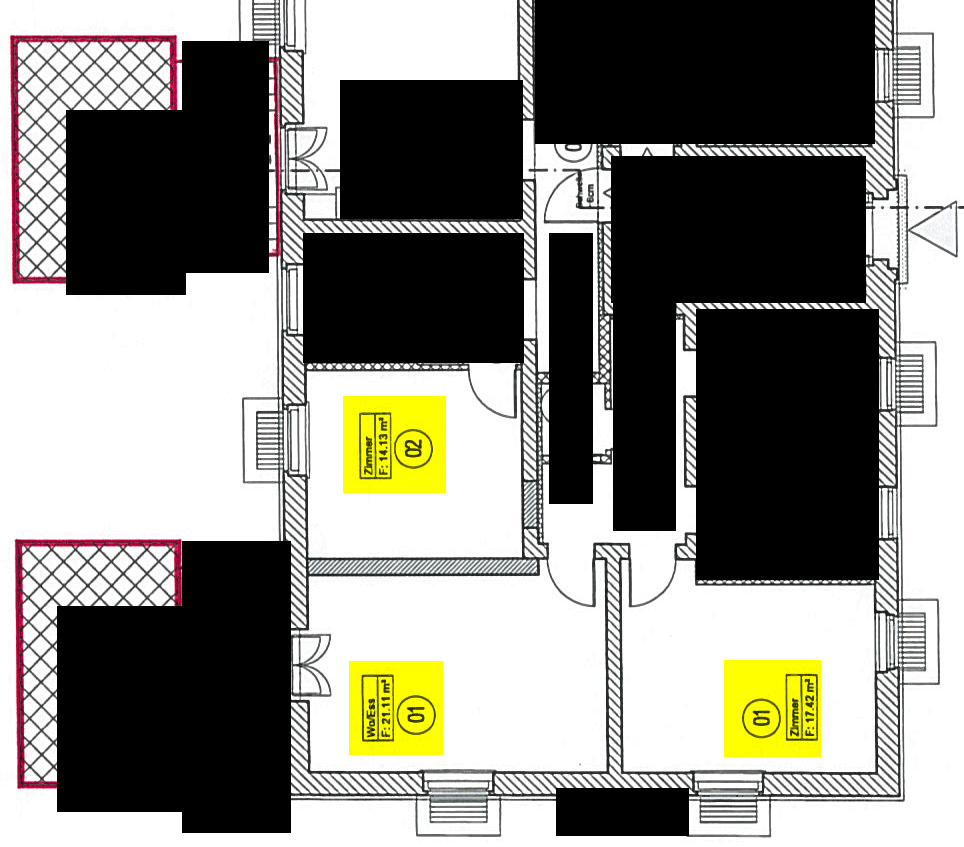
Now, let us scan the construction plan and get a PDF file from it. No OCR, just plain image. Then, we get wrong square meter numbers at the three places ![]() (Yeah, couldn’t believe it, too). The screen shots of the erroneous places are organized in the below table. There is one additional line in the table for the original patches. The Xerox WorkCentre 7535 always produced the same errors; this is why we only need one line for it in the table. In contrast, the WorkCentre 7556 randomly produced different numbers, this is why I present three lines for three runs with different errors.
(Yeah, couldn’t believe it, too). The screen shots of the erroneous places are organized in the below table. There is one additional line in the table for the original patches. The Xerox WorkCentre 7535 always produced the same errors; this is why we only need one line for it in the table. In contrast, the WorkCentre 7556 randomly produced different numbers, this is why I present three lines for three runs with different errors.
| Run / Machine | Place 1 | Place 2 | Place 3 |
|---|---|---|---|
| Original, aus einem Tif-Scan entnommen, Korrektheit verifiziert |  |
 |
 |
| Xerox WorkCentre 7535 |  |
 |
 |
| Xerox WorkCentre 7556, Run 1 |  |
 |
 |
| Xerox WorkCentre 7556, Run 2 |  |
 |
 |
| Xerox WorkCentre 7556, Run 3 |  |
 |
 |
I know that the resolution is not too fine, but the numbers are clearly readable. Additionally, obviously, these are no simple wrong pixels, but whole image patches are mixed up or copied. I repeat: This is not an OCR problem, but of course, I can’t have a look into the software itself, maybe OCR is still fiddling with the data even though we switched it off.
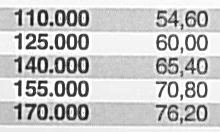
Next example: Some cost table, scanned on the WorkCentre 7535. As we are used to, a correct-looking scan at the first glance, but take a closer look. This error was found because usually, in such cost tables, the numbers are sorted ascending.
| Before | After |
|---|---|
 |
 |
The 65 became an 85 (second column, third line). Edit: I’m getting emails telling me that also a 60 in the upper right region of the image became a 80. Thanks! This is not a simple pixel error either, one can clearly see the characteristic dent the 8 has on the left side in contrast to a 6. This scan is several weeks old – no one can say how many wrong documents have been produced by the Xerox machines in the mean time.
Technical Detail
Here some tech detail in order to enable you reproduce the errors:
Machine 1
- Model: Xerox Workcentre 7535
- Software versions: 061.121.201.09700 and 061.121.222.06508 (the service told us the latter one was the newest)
- Parameters of the scan: Click for screenshot, unfortunately it is in German
Machine 2
- Model: Xerox Workcentre 7556
- Software versions: 061.121.201.09700
- Parameters of the scan: Click for screenshot, unfortunately it is in German
List of reportedly affected machines
- WorkCentre 7530
- WorkCentre 7328
- WorkCentre 7346
- WorkCentre 7545
- WorkCentre 7535
- WorkCentre 7556
- Xerox ColorQube 9203
- Xerox ColorQube 9201
- Xerox ColorQube 8700
Note that I did not reproduce the Error on all of these myself, so except for the 7535 and 7556, take the information as hearsay.
Reproducing the error
After the cost table, I printed some numbers, scanned them, OCRed them and compared them to the original ones. As the OCR produces errors, by itself, one obviously has to check by hand for false positives when performing this. I took Arial, 7pt as a test font, and the WorkCentre 7535 with the newer of the aboved named Software version as a test machine. The scan settings were like above. And again, a lot of sixes were replaced by eights: (only a few of the errors are marked yellow for the sake for laziness):
| Before | After |
|---|---|
 |
 |
Observe how the sixes around the false eights look correct. Also the false eights contain the characteristic dent again, so whole image patches have been replaced again.
In case you want to have a look for yourself:
- An error-free TIF scan of the page
- The first page of the PDF scan with a few marked false eights mixed in by the 7535 WorkCentre. The OCR was added by me later to be able to mark the numbers nicely, so be aware it may not be the original file, even though the image data in it is.
- Due to the popular demand: All pages of the PDF scan without any post processing, just like they came out of the 7535. Lots of pages.
Assumptions on the causes (EDIT)
The error does not occur if PDFs are scanned with OCR, or TIFs are scanned (the latter seems plausible, as the pure image data should be saved into the TIF). Additionally, there seems to be a correlation between font size, scan dpi used. I was able to reliably reproduce the error for 200 DPI PDF scans w/o OCR, of sheets with Arial 7pt and 8pt numbers. Overall it looks like some sort of compression algorithm using patches more than once (I think I could even identify some equally-pixeled eights).
Edit: It seems that the above thought was not that wrong at all. Several mails I got suggest that the xerox machines use JBIG2 for compression. This algorithm creates a dictionary of image patches it finds “similar”. Those patches then get reused instead of the original image data, as long as the error generated by them is not “too high”. Makes sense.
This also would explain, why the error occurs when scanning letters or numbers in low resolution (still readable, though). In this case, the letter size is close to the patch size of JBIG2, and whole “similar” letters or even letter blocks get replaced by each other.
Of course, if Xerox would have chosen the patch size in a way enabling whole, readable letters to fit into the patches, this would be grossly negligent. Also, it would shed light on how these machines are tested, as when using some patch-based compression algorithm, it kind of suggests itself to test it with low-resolution, albeit still readable letters.
I am curious how Xerox is going to react and what will come out. Until then, thanks for spreading the word, please go on doing so – and of course, I am looking forward to getting further helpful emails!




{kind=link}
{kind=link}