Xerox scanners/photocopiers randomly alter numbers in scanned documents (original report)
[Ed. Note: After this post, Mr. Kriesel had a follow-up call with Rick Dastin, Corporate Vice President Office and Solutions, and Francis Tse, Imaging System Architect at Xerox Corporation. His post about it is here. My previous post, Confused photocopiers randomly rewriting scanned documents, concerns an article by Peter Bright from arstechnica.com about Mr. Kriesel’s […]
Confused photocopiers randomly rewriting scanned documents (short version)
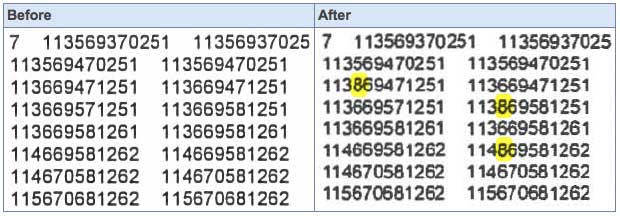
Scans can’t be trusted as Xerox machines switch numbers around. By Peter Bright from arstechnica.com: Photocopiers exist to produce close enough replicas of original documents. Traditionally, they just spit out the result onto paper. Most copiers these days can operate as (generally rather large) scanners, generating PDFs, TIFFs, or other electronic representations. But some Xerox […]
Japanese Scientists Develop System That Can Visualize Dreams Based on Brain Activity

Scientists in Japan have developed a dream decoding system that can create a visualization of a person’s dream. Developed by researcher Yukiyasu Kamitani and his Kyoto-based team, the system uses a functional MRI to analyze brain activity and a learning algorithm to create visualizations from the brain data. While the researchers report that the system […]