In the U.S., today is Thanksgiving, billed as a day of giving thanks for our blessings, in commemoration of the story of the Pilgrims and the Wampanoag Indians feasting together. (You’re supposed to do it with your birth family, unless you’re too queer or trans or many other marginalized groups, of course. Or too political. So many of us spend the day with chosen family if we can. )
For many Native American people, however, today is the Day of Mourning, marking a characteristic and systemic way in which the shameful history of colonization and genocide by Europeans of Native Americans has been elided and erased. Find out whose land you stand on. See here and here for starters, and beautiful image results from a Google search on “Native American script.”
I wasn’t able to find any reputable references to writing or transcribing the Wampanoag language, but I did find this 2002 article about the relative ease of rendering the Cherokee and Inuiktitut (Inuit languages) syllabaries in Unicode type. It’s great that people are interested in keeping the first languages of this country and continent alive.
My love to you all, however you are spending the day.
See also my blog posts First Nations Font Thursday 2 and First Nations Font Thursday 3.
Typesetting Native American Languages
This paper was refereed by the Journal of Electronic Publishing’s peer reviewers.
All the native American languages spoken today are written either in some Latin alphabet, augmented with “accented” letters, or in a syllabary, a set of indivisible syllabic symbols, each of which represents a syllable. The Apache and the Navaho languages are among the native American languages that use a Latin alphabet, while Cherokee, Inuiktitut, and Cree are among the languages that use modern syllabaries. Syllabaries, common in ancient scripts, were used by the Maya and the Epi-Olmec people of Mesoamerica.
Because a syllabary is less expressive than an alphabetic script, it can be transcribed in an alphabetic script without losing meaning. Students of the Cherokee language learn a Latin transcription of the syllabary to make it easier to learn Cherokee. The same characteristics that allow Cherokee to be transcribed into the Latin alphabet allow the creation of typesetting tools for syllabaries. A modern typesetting tool designed to handle syllabaries should allow users to type the symbols either directly (e.g., using a Unicode editor if the script is supported by the Unicode Standard, or by some editor that supports a special character set), or by using some standard Latin transcription. (Unicode provides a unique computer-readable number — called a code point — for every character; this number works across platforms, programs, and languages.)
This article is about Omega, a modern typesetting system based on TeX, that by default accepts Unicode text files, but is capable of handling any imaginable input encoding. In addition, it introduces a number of features that make the lives of tool designers quite easy. I used these features to develop a number of tools that ease the preparation of Cherokee and Inuktitut language documents.
TeX and LaTeX
TeX is a legendary computer program designed by Donald E. Knuth, the famous professor of computer science at Stanford University. It is a digital typesetting engine, a computer program that does the work of a typographer, describing the appearance of the printed page (Knuth, 1993). TeX processes an input file that contains both text and typesetting commands. Leslie Lamport designed the LaTeX markup Language (Lamport, 1994) that sits on top of the TeX typesetting engine to facilitate the creation of input files. Because many people are familiar with LaTeX but do not know its relationship to TeX, they mistakenly think LaTeX and TeX are two different programs. Yet, TeX produces a device independent (DVI) file describing the text and graphic elements on a page that can be further processed to generate other page-description languages such as PostScript output. Knuth also designed METAFONT, which implements a different font description and generation language (Knuth, 1992).
Although the development of TeX has been frozen since Knuth has decided not to develop further TeX and METAFONT, new typesetting engines that extend TeX’s capabilities are still emerging. The most notable TeX extensions are: pdfTeX (Thanh et al., 1999), which can directly produce PDF files; e-TeX (NTS Team and Beiettenlohner, 1998), which is a TeX extension that increases TeX’s capacity and capabilities by allowing bidirectional typesetting; and Omega which is the Unicode extension of TeX capable of taking Unicode input and typesetting it in many writing directions (Syropoulos et al., 2002). In addition, Omega can produce XML and MathML content. Note that MathML is an XML application that is primarily intended to facilitate the use and reuse of mathematical and scientific content on the Web. Using Omega, a typesetter can write pre-processors that bridge Unicode and typesetting. (Note that Lambda is a nickname for LaTeX when used with Omega.)
Cherokee
Cherokee is an Iroquian language spoken by some 20,000 people, mostly as a second language. There are only two remaining dialects: Oklahoma (spoken by approximately 17,000 people) and North Carolina (spoken by the other 3,000 people).
The Cherokee script was developed in the 19th century by a Cherokee named  Sequoya (who used the name George Guess or George Giss when dealing with white men). Some think that Sequoya was the only person ever to develop a script alone, but there are others who have done so. For example: the Greek St. Clement of Ohrid developed the Cyrillic script (Kirilitsa), in a form close to the one still in use today, based on the earlier work of the Greek monks St. Cyril; St. Methodius developed a Slav script called Glagolitsa; Reverend James Evans created the writing system of the Inuktitut langauge based on earlier work on the Cree language, which, in turn, was based on work on the Ojibway language; and Afaka Atumisi invented the Ndjuka syllabary.
Sequoya (who used the name George Guess or George Giss when dealing with white men). Some think that Sequoya was the only person ever to develop a script alone, but there are others who have done so. For example: the Greek St. Clement of Ohrid developed the Cyrillic script (Kirilitsa), in a form close to the one still in use today, based on the earlier work of the Greek monks St. Cyril; St. Methodius developed a Slav script called Glagolitsa; Reverend James Evans created the writing system of the Inuktitut langauge based on earlier work on the Cree language, which, in turn, was based on work on the Ojibway language; and Afaka Atumisi invented the Ndjuka syllabary.
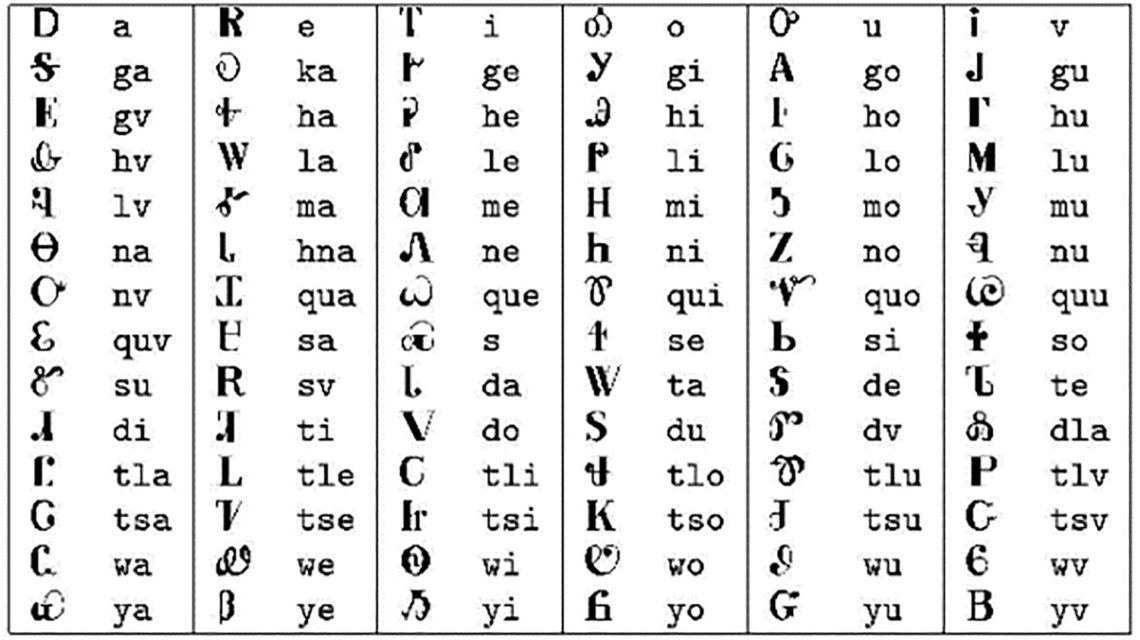
Sequoya’s Cherokee syllabary consists of eighty-four symbols, each of which stands for a syllable. As with other syllabaries, it is not possible to use symbol combinations to create sounds alien to the language such as th, sh, or ch. In addition, Cherokee does not have the sounds f, v, p, b, th, r, or z; m is also rare. It has one sound that English does not, a vowel pronounced “unh” as in the phrase “huh?” 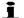 . Huh in Cherokee would be written
. Huh in Cherokee would be written  . The other vowels are “a” (
. The other vowels are “a” ( pronounced as the “a” sound in “father”), “e,” (
pronounced as the “a” sound in “father”), “e,” ( pronounced as the “a” sound in “way”), “i” (
pronounced as the “a” sound in “way”), “i” (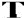 pronounced as the “e” sound in “bee?”), “o” (
pronounced as the “e” sound in “bee?”), “o” (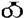 pronounced as “oh”), and “u” (
pronounced as “oh”), and “u” ( pronounced as “ooh”). The table below shows the complete Cherokee syllabary. Note that the table does not contain the symbol “nah,” which is included in the Unicode support of the Cherokee script. It is not used anymore because it is almost identical in pronunciation to the “na” symbol.
pronounced as “ooh”). The table below shows the complete Cherokee syllabary. Note that the table does not contain the symbol “nah,” which is included in the Unicode support of the Cherokee script. It is not used anymore because it is almost identical in pronunciation to the “na” symbol.
 Cherokee syllabary
Cherokee syllabaryInuktitut
Inuktitut is the language of the Inuit (also known as “Eskimos,” but the term is considered offensive by Inuit who live in Canada and Greenland). The language is spoken by approximately 152,000 people in Greenland, Canada, Alaska, and the Chukotka Autonomous Okrug, which is located in the far northeast region of the Russian Federation. The Inuktitut syllabics are used by Inuit who live in Canada, especially in the new Canadian territory of Nunavut. This writing system was invented by Reverend James Evans, a Wesleyan missionary. The table below shows the Inuktitut syllabics and the Latin transcription of the Inuktitut symbols. (Note that the Inuktitut script is supported by Unicode and it is actually part of the Unified Canadian Aboriginal Syllabics section of the Unicode Standard.)
 Inuktitut syllabary
Inuktitut syllabaryCurrently, there are two Inuktitut orthographies (orthography is the art or study of correct spelling according to established usage): the Anglican (used mainly in Nunavut) and the Catholic (used mainly in Quebec). They differ in the way they write “long” vowels — syllables with two identical vowels. The Anglican orthography places a dot above a short syllable to make it long; the Catholic orthography uses two symbols. Note the different representations of the word “ataata” (father) below.
 in Inuktitut orthographies") “ataata” (father) in Inuktitut orthographies
“ataata” (father) in Inuktitut orthographiesTypesetting Syllabaries with Lambda
The typesetting tools I designed for Cherokee and Inuktitut text can be used with the Omega typesetting system, as they heavily rely on the Omega Translation Processes (OmegaTPs). Technically, an OmegaTP is a deterministic finite state automaton (an abstract “machine” — a mathematical function — used in the study of computation and languages) that is used to transform an input character stream. For example, an OmegaTP can transform an ISO-Latin-1 input character stream to a UCS-2 character stream. While we can get exactly the same effect if we are using some external preprocessor and TeX, preprocessors are notably difficult to use. So we built a system that would not require a preprocessor.
First we had to identify the valid coding for the Cherokee or Inuktiut text. We determined that since both syllabaries are supported by the Unicode standard, we would allow Unicode input files (either UCS-2 or UTF-8). Since both syllabaries have standard Latin transcriptions, we decided to allow that, too. Finally, there have been a number of eight-bit character sets for Inuktitut, so we chose one. To work with Unicode input, we used Unicode-encoded virtual fonts. A virtual font is a mechanism by which we create a font that actually draws glyphs from existing fonts. To create a new virtual font, we need to build a virtual property list file, which describes the virtual glyphs of the font, which are drawn from actual fonts, as well as their dimensions, kerning pairs, and ligature pairs. In addition, virtual fonts are used to create new glyphs such as accented letters, underlined glyphs, and so on.
For Cherokee, Omega uses a PostScript version of the official Cherokee TrueType font developed by Tonia Williams of the Oklahoma Cherokee Nation, which does not contain any Latin glyphs and does not follow Sequoya’s numbering system. For the Inuktitut language, it uses a PostScript version of the Nunacom TrueType font developed by Nortext, a Canadian company that pioneered Aboriginal-language typesetting fonts in the early 1980s. The virtual fonts for the Inuktitut language draw glyphs from the Nunacom font, the standard Computer Modern typefaces that accompany every TeX installation, and a typeface that I manufactured, to complement the fonts in the standard TeX distribution.
For the Cherokee script we had to design only one OmegaTP, since there is no 8-bit Cherokee codepage to the best of our knowledge. The design of the OmegaTP was almost straightforward except for a simple problem: the handling of the syllable that occurs when an “s” is not followed by an “a,” “e,” “i,” “o,” “u,” or “v.” OmegaTP “pushes back” the character that immediately follows the character “s”. Otherwise, we simply generate the corresponding symbol. For instance, if the head of the input stream is “se”, OmegaTP will return the character 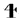 and so on. For example, the input “elohinodohiyigesesti” (peace on Earth) will be typeset as
and so on. For example, the input “elohinodohiyigesesti” (peace on Earth) will be typeset as
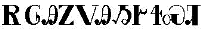
Typesetting Inuktitut with Lambda is more complex than typesetting Cherokee because we actually have one Latin transcription that can produce different output, depending on the orthography that is assumed, and a valid eight-bit codepage. Thus, we had to code three OmegaTPs to handle all possible cases. In addition, we had to offer users the ability to choose the input method in a transparent way. So, we offer the options: “nunavut,” “quebec,” and “inscii.” We had many of the same problems with Inuktitut as we had with Cherokee, such as characters that can either stand alone or start a syllable. The table below shows the layout of the ISCII character set that corresponds to the OmegaTP implements.
 ISCII Character Set
ISCII Character SetSince Omega can perform word hyphenation if instructed, we coded the hyphenation rules of the Inuktitut language so that the tools are complete.
Omega and the Other Native American Languages
In addition to the Cherokee and the Inuktitut languages, the Blackfoot, the Dene (Carrier), the Cree and the Naskapi languages use a non-Latin script. Their scripts are included in the PDF file Unified Canadian Aboriginal Syllabics section of the Unicode Standard. Therefore, based on our previous experience, it is a rather straightforward task to create similar tools. However, we feel that a far better idea is to create a set of tools that can be used to typeset any American language that does not use the Latin script. This may seem quite restrictive, but the tools that are available today are quite adequate to handle those American languages that use the Latin script.
Of course, there are some languages that use the Latin script, like Smalgyax and Tlingit, which have some special letters (e.g., underlined letters), and the Apache language, which has some letters that are common in some European languages, but text in these languages can be processed with tools that are already widely available. For example, the Tlingit phrase 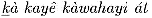 (rights), the Smalgyax phrase
(rights), the Smalgyax phrase 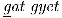 (rights), and the Apache word
(rights), and the Apache word  (fish) and
(fish) and 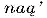 (corn), have been typeset with these standard methods. Of course, it is possible to create special virtual fonts that will contain all these special Latin letters (Syropoulous et al., 2002).
(corn), have been typeset with these standard methods. Of course, it is possible to create special virtual fonts that will contain all these special Latin letters (Syropoulous et al., 2002).
The situation is rather different when it comes to the typesetting of ancient American scripts such as the Epi-Olmec and the Maya scripts. First of all, the symbols of these scripts are not defined in the Unicode standard. In addition, the writing direction is not Western (i.e., from the left to right and from the top to the bottom of the page), instead their writing direction is actually identical to the writing direction of the classical Mongolian Uighur script (i.e., from the top to the bottom and from the left to the right of the page). We are working on a tool that will allow researchers to typeset the few Epi-Olmec texts that are available. An Epi-Olmec font is almost ready. The font itself is based on the description of the script as presented in Epi-Olmec Hieroglyphic Writing. Since the script is roughly a syllabary, we have created a simple OmegaTP that can handle a subset of the syllabary, but we have found that the commands that can be used to set the writing direction do not function well with our font. So we had to enhance the OmegaTP to actually produce a typesetting command and not merely a translation. To see the difference, consider the following examples:
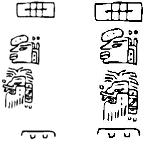
The symbols on the left were typeset by merely relying on Omega’s capabilities; those on the right were typeset by using an enhanced OmegaTP. Of course, there is much work to do and so we do not believe the tools will be available anytime soon.
Conclusions and Future Work
We have presented the tools that we have developed for the typesetting of Cherokee and Inuktitut texts. The tools are freely available from the Comprehensive TeX Archive Network (CTAN) at ftp://ftp.dante.de or ftp://ftp.tex.ac.uk or directly from me. There is still much work to be done on these tools — especially the Cherokee tool — but they can be used as a model to create new tools for other typesetting needs. As the forthcoming versions of Omega will be able to understand Unicode surrogates, it will even be possible to apply the ideas presented here to the problem of typesetting Byzantine and Western music text.

Apostolos Syropoulos, president and founding member of the Greek TeX Friends Group, has written several LaTeX packages to facilitate Greek language typesetting with LaTeX. He is the author of the first book on LaTeX in Greek, LATEX. He is a co-author of TEX and Electronic Typesetting: 110 Questions and Answers, the Greek FAQ for TeX, LaTeX, METAFONT and fonts in general. He has a B.Sc. in Physics, a M.Sc. in Computer Science and a Ph.D. in Theoretical Computer Science. He is currently working on books on LaTeX and Digital Typography and on programming with Perl. He has written many articles on computing in general and typesetting in particular. His scientific interests include programming language theory, concurrency, logic (especially linear and fuzzy logic), and electronic typesetting with TEX. He can program in Pascal, FORTRAN, Perl, Modula-2, C/C++, LML, SML, Prolog, and Java, and he speaks Greek, English, a little Swedish, and some Russian. His Web site is at http://obelix.ee.duth.gr/~apostolo/. He may be reached by e-mail at apostolo@ocean1.ee.duth.gr.
References
Kaufman, T., and Justeson, J. (2001, March). Epi-Olmec Hieroglyphic Writing. Available on line: http://www.albany.edu/anthro/maldp/papers.htm
Knuth, D.E. (1992). The Metafont Book. Volume C of Computers and Typesetting. Reading, MA: Addison-Wesley.
Knuth, D.E. (1993). The TeX Book. Volume A of Computers and Typesetting. Reading, MA: Addison-Wesley.
Lamport, L. (1994). LaTeX: A Document Preparation System, 2nd ed. Addison-Wesley.
NTS Team and Beiettenlohner, P. (1998). The e-TeX manual, Version 2. MAPS, 20, 1998, 248-263.
Syropoulos, A., Tsolomitis, A., and Sofroniou, N. (2002). Digital Typography using LaTeX. New York: Springer-Verlag.
Thanh, H.T., Rahtz, S., and Hagen, H. (1999). The pdfTeX users manual. MAPS, 22, 1999, 94-114.
Links from this article
Comprehensive TeX Archive Network (CTAN), http://www.ctan.org
Donald E. Knuth, http://www-cs-faculty.stanford.edu/~knuth
Epi-Olmec Hieroglyphic Writing, http://www.albany.edu/anthro/maldp/papers.htm
Nortext, http://www.nortext.com
Oklahoma Cherokee Nation, http://www.cherokee.org
Unicode Standard, http://www.unicode.org
Unified Canadian Aboriginal Syllabics section of the Unicode Standard, http://www.unicode.org/charts/PDF/U1400.pdf



